

Duplicate content is a big issue for Google indexing and is a source of headache for website owners.
The most annoying part is that you may be completely unaware that some of your web pages have duplicates, which is why this is a worthwhile read.
In this ultimate guide to fixing duplicate content, I’ll describe what duplicate content is, what causes it, how it affects your SEO, and the best practices to get rid of duplicates.
If ranking high on Google search engine result pages means a lot to you, then you should keep on reading.
Table of Contents
What Is Duplicate Content?
Content is said to be duplicated when the same replica or something close to it exists on the internet in the same language and more than one location.
It’s the same content or something similar on multiple web pages.
It could be cross-domain or on the same website.

Most of the time, this occurrence is not deliberate or deceptive and could arise from a technical mishap.
However, in some cases, website owners duplicate their content intentionally so that they can get more traffic or manipulate SEO rankings.
Besides confusing search engines, it brings no additional value to your visitors as the user experience is poor. They view repeats of the same content or substantial content blocks in the search result pages.
Pages that have no or little body content can also be called duplicate content.
Two types of duplicate content exist—onsite and off-site duplicates.
- Onsite duplicates are the same content present on more than one unique web address or URL on your platform. This type of duplicate content can be checked by your web developer and website admin.
- Off-site duplicates are duplicates published by more than one website. This type of duplicate cannot be directly controlled and needs a third party working with the offending website owners to handle it.
The result of duplicate content is that your contents confuse search engine robots, so, search engines like Google don’t know which website to rank higher on the search engine results pages.
Duplicate Content – Impact on SEO?
If you’re improving your SEO metrics or you have them already, duplicate content is harmful.
Here are some reasons why:
- Unfriendly or undesirable web addresses in the search results;
- Affects the crawl budget;
- Backlink dilution;
- Syndicated and scraped content outranking your website;
- Lower rankings.
How do the following affect your SEO?
1. Unfriendly or undesirable web addresses in the search results
If a web page on your platform has three different web addresses like so:
- com/page/
- com/page/?utm_content=buffer&utm_medium=social
- com/category/page/
The first is ideal and should be the one indexed by Google.
However, because there are other alternatives with the same content, if Google displays the other URLs, you’ll get fewer visitors because the other two URLs are unfriendly and not as enticing as the first.
2. Backlink Dilution

Backlinks are a good source for boosting SEO rankings.
That’s why you should run away from anything that can weaken this potent SEO arsenal.
When you have the same content on multiple web addresses, all of those addresses attract backlinks.
Therefore, the various URLs share this “link equity”.
3. Crawl Budget
Through the mechanism of crawling, Google locates updates in your content by following URLs from your older pages to the latest ones.
Google also recrawls pages they have crawled previously to take note of any changes in the contents.
When you have duplicates on your website, the frequency and speed with which Google robots crawl your updated and new content are reduced.
That culminates in the indexing and reindexing of new and updated content.
4. Your Website Is Outranked by Scrapped Content
When other websites seek your permission and republish the content on your web pages, it’s called syndication.
However, in some situations, website owners can just duplicate your content without your permission.
Each one of these scenarios can lead to duplicate content, and when these websites outrank your website, problems begin to surface.
5. Lower Rankings
Duplicate content ultimately leads to lower rankings on search engine results pages.
That is because when you have duplicate content on multiple web pages, search engine robots will be confused about which URL to suggest to potential visitors.
Therefore, search engines will only display yours after the other relevant websites have been shown, which means lower rankings for you.
Duplicate Content – Causes
There are a lot of reasons why duplicate content arises. Most of the time, duplicate content arises as a result of unnatural reasons like technical problems.
These technical issues arise at the level of developers. Here are a couple of reasons why duplicate content comes up.
1. URL Misconception
This technical issue arises when your website developer powers your website in such a way that even though there’s only a single version of that article in the database, the website software permits it to be assessed from more than one web address or URL.
Put another way, the database has only one article, which your developer identifies with the unique ID.
However, whenever users make a search query relating to that article, the search engine crawls and indexes that content through multiple URLs, which, for the search engine, is the unique identifier for that content.
Solution to Cause
2. WWW vs. non-WWW and HTTPS vs. HTTP
Take a look at these URLs:
- http://abcdef.com – HTTP, non-www variant.
- http://www.abcdef.com – HTTP, www variant.
- https://abcdef.com – HTTPS, non-www variant.
- https://www.abcdef.com – HTTPS, www variant.
Visitors can visit almost all websites through any of the four URL variations above.
You can use HTTPS or the less secure HTTP version, which can be either “www” or “non-www”.
If your website developer doesn’t adequately set up your website server, users can access your content through two or more of the above alternatives, which can cause problems with content duplication.
Solution to Cause
- Apply redirects to your website so that visitors can enter your platform through one location only.
3. Session IDs
Session IDs are a way for website owners to track and store information about visitors to their website.
This technical error is commonly found in online stores where each visit, called a “session,” is created and stored to track details such as the visitors’ activities on your website and the items they put in the shopping cart.
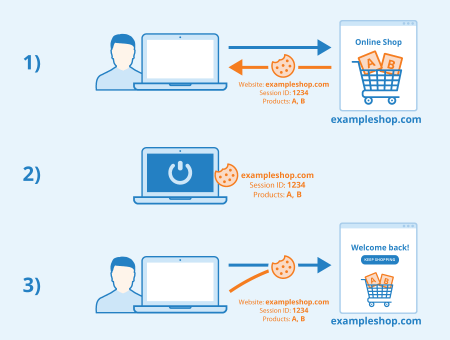
The unique identifier for that session is what is called a “session ID,” and it is unique to that particular session.
The session ID is added to the URL, and that creates another URL.
A session URL usually looks like this:
- Example: com?sessionId=huy4567562pmkb5832
Therefore, to summarize, session IDs track and store your visitors’ activities by adding a long string of alphanumeric codes to the URL.
Even though this seems like a worthy cause, it still counts as duplicate content, sadly.
Solution to Cause
- Use canonical URLs to the original web page that is SEO-friendly.
4. Sorting and Tracking Parameters
When website owners and developers want to sort and track certain parameters, they make use of a type of URL called “parameterized URLs.”
A good example is the UTM parameterized URL in Google Analytics that tracks the visits of users from a newsletter campaign.
They can look like this:
Example of original URL:
- http://www.abcdef.com/page
An example of a UTM parameterized URL:
- http://www.abcdef.com/page?utm_source=newsletter
Even though URL parameters serve some good purposes, like displaying another sidebar or altering the sort setting for some items, they, of course, do not change your web page’s content.
Therefore, because the content of the two web addresses is the same, to search engines, UTM counts as duplicate content.
Solution to Cause
- Use canonical URLs for all the parameterized links on your website to the SEO-friendly variants without the parameters for sorting and tracking.
5. URL Parameter Order
The order in which URL parameters are arranged also contributes to duplicate content issues.
Example:
- In the CMS, URLs are created in the form of /?P1=1&P2=2 or /?P2=2&P1=1.
P1 and P2 stand for Parameter 1 and Parameter 2, respectively.
Even though the CMS sees the two URLs as the same since they offer the same results, search engines see them as two different URLs, flagging them as duplicate content.
Solution to Cause
- Your developer or programmer should use the same consistent approach to order parameters.
6. Content Syndication and Scrapers
This issue arises when your content is used by other website owners without your permission and it is common with popular websites.
They don’t link to your website, and search engines just see the same or almost the same content on multiple pages.
Solution to Cause
- Reach out to the webmaster of the website involved and ask for removal or accreditation.
- Self-referencing canonical URLs.
7. Comment Pagination
This problem arises when your CMS, like WordPress, paginates the comments on the affected web page.
This creates multiple versions of the same web address and content.
Example:
- com/post/
- com/post/comment-page-2
- com/post/comment-page-3
Solution to Cause
- Turn comment pagination off
- Use a plug-in to noindex your paginated pages. Yoast is a good one.
8. Printer-Friendly Pages
When you have printer-friendly web pages, those pages contain the same content as the original pages but have different URLs.
Example:
- com/page/
- com/print/page/
When a user searches and Google is indexing websites related to the search query, both versions of the same web page will be indexed by Google, except if you block the printer-friendly versions.
Solution to Cause
- Use canonical URLs to convert the printer-friendly version into the original version.
9. Mobile-Friendly Pages
Mobile-friendly pages have the same problem as printer-friendly pages. Both are duplicate content and are flagged by search engines.

Example:
- com/page/ – original content
- abcdef.com/page/ – mobile-friendly URL
Solution to Cause
- Use canonical URLs for the mobile-friendly version.
- Employ rel=“alternate” to inform search engines that the mobile-friendly link is a variant of the desktop link.
10. Accelerated Mobile Pages
Accelerated mobile pages that help web pages load faster are also duplicate content.
Example:
- com/page/
- com/amp/page/
Solution to Cause
- Use canonical URLs to convert the AMP version into the non-AMP variant.
- You can also employ a self-referencing canonical tag.
11. Localization
When your website serves people in different regions but the same language, it creates room for duplicate content.
For instance, your website serves audiences in the UK, US, and Australia, and you create different versions for them.
These website variants will contain virtually the same information, besides currency differences and other specifics, and therefore, still count as duplicate content.
It’s important to point out that content that is translated into another language doesn’t count as duplicate content.
Solution to Cause
- Hreflang tags are very effective in telling Google the relationship between the alternate websites.
12. Attachment URLs for Images
Some websites have image attachments with dedicated web pages.
These dedicated web pages only show the image and nothing else, and this leads to duplicate content because the duplicate content exists across all the auto-generated pages.
Solution to Cause
- Turn off the dedicated pages feature for your CMS images.
- If it’s WordPress, use Yoast or any other plug-in.
13. Staging Environment
In some scenarios, like when you want to change something on your website or install a new plug-in, it’s necessary to test your website.
You don’t want to do this on your live website, especially when you have a massive number of visitors daily.
The risk of something going awry is too high.
Enter the staging environment.
Staging environments are another version of your website, which may be a replica of the website or something slightly different than what you use for testing functions.
This becomes problematic when Google identifies these alternate URLs and indexes them.
Solution to Cause
- HTTP authentication is a good way to guard your staging environment.
- VPN access and IP whitelisting are also effective.
- Apply the robot’s noindex command if the link is indexed already so that it can be taken out.
14. Case-Sensitive URLs
Google is case-sensitive to URLs.
Example:
- com/page
- com/PAGE
- com/page
All of these URLs are distinct and treated differently by Google.
Solution to Cause
- If you’re using internal links, use a consistent format. Don’t use internal links for multiple URL variants.
- Use canonical URLs.
- Use redirects.
Conclusion
Duplicate content creates a lot of confusion during Google indexing and, besides lower rankings for your website, duplicate content can affect user experience.
That is why you should apply the methods above and rid yourself of duplicates once and for all.
Canonical URLs are a good place to start.