
Did you just get an “Indexed, though blocked by robots.txt” message from Google Search Console? You don’t know what it is, if it is serious, or what to do? No worries! In this article, I will show you all there’s to know about this issue, and guide you step-by-step on the fixes. Read on!
Table of Contents
What is Shopify robots.txt?
Before everything else, let’s talk about what the robots.txt is first, as this is where all the “why” and “how to fix” will be coming from.
Shopify robots.txt is a file that instructs search engine robots (also known as “crawlers” or “spiders”) which pages or sections of a website to not crawl or index. For example, if your robots.txt file includes the line “Disallow: /checkout”, the robot will not crawl or index any pages within the checkout section of the website.
As a Shopify store owner, this is where you join the conversation. Shopify automatically generates a robots.txt file for each store, which can even be edited and customized by the store owner in the Shopify admin. Therefore, you get to control which web pages are to be indexed. And in case you didn’t know, this can greatly affect your store’s SEO performance. But first, let’s see how to access this said file.
Where can I Access Robots.Txt File in Shopify?
You can access the robots.txt file in your Shopify store by adding “/robots.txt” to the end of your store’s UR. For example, if your store’s URL is “www.abcstore.com”, you can access the robots.txt file by visiting “www.abcstore.com/robots.txt” in your web browser.
Or simply log in to your Shopify admin. Next, go to Online Store > Preferences > Search engine listing preview > Edit robots.txt”
Shopify’s Default Robots.txt Rules
Shopify’s default robots.txt file automatically prevents Google from indexing pages that are not relevant to searches or could cause duplicate content. And of course, this is good for your store’s SEO.
By default, Shopify’s robots.txt file includes the following instructions:
- Disallow: /checkout
- Disallow: /cart
- Disallow: /orders
- Disallow: /account
- Disallow: /search
- Disallow: /apps
- Disallow: /services
These mean, any pages within the checkout, cart, orders, account, search, apps, and services sections of your store shouldn’t be indexed.
Additionally, the robots.txt file can include the instruction “Allow: /” “Sitemap: https://mystore.com/sitemap.xml” which points the robots to the store sitemap, offering a list of all URLs on the website that should be indexed.
By limiting the number of less-value or redundant pages indexed, search engines can direct users to more relevant pages, attracting more targeted traffic.
So far so good, Shopify!
What Does “Shopify indexed though blocked by robots.txt” Mean?
This means that some of your pages are not meant for indexing but still get indexed by Google, even after you have blocked them in your store’s robots.txt file. Whenever this happens, you can tell your instructions in the robots.txt file are not being followed.
This can happen for various reasons, and here are some:
- Misconfiguration in the robots.txt file: The instructions provided in the file may be incorrect or not properly formatted.
- Robots.txt file deletion: The robots.txt file may have been accidentally deleted or removed.
- Robots.txt file not accessible: The robots.txt file may not be accessible by search engine crawlers. If the server is not configured properly. This could be due to a misconfigured firewall, incorrect file permissions, or other server-side issues.
- Third-party apps: Some third-party apps can affect the robots.txt file and cause the pages to be indexed despite being blocked by the file.
- Sitemap: Even if a page is blocked by the robots.txt file, it may still be included in the website’s sitemap, which can lead to the page being indexed by search engines.
- Links on other pages or dynamic URLs: Despite being blocked by the store’s robots.txt file, some pages may still be crawled and indexed by search engine robots through links on other pages or dynamic URLs.
Some bloggers may claim that it’s not a big deal. But that’s not entirely accurate. It’s likely that Google will de-index the page in the future, which means it will no longer be included in Google’s search results. If this happens to be an important page to drive in traffic to your store, obviously, you face decreased visibility and revenue.
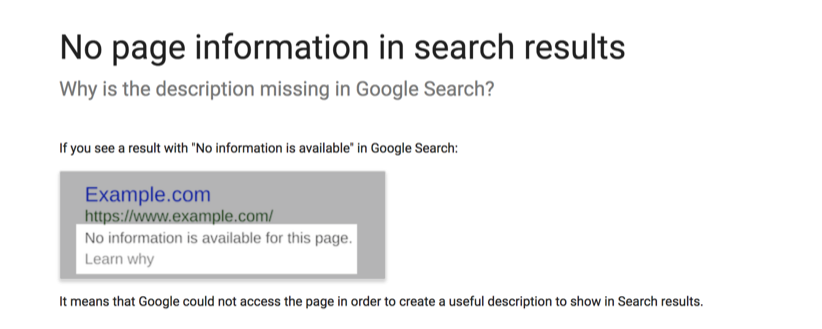
Alternatively, Google may show a warning message in search results instead of your meta description. And that can negatively impact your brand’s reputation. I mean, just take a look at the example below:

Stuff like this gives potential users the impression that you aren’t professional, nor are you a top reliable brand.
Maybe you do want those pages to be indexed, but they were accidentally blocked on the robots.txt file. Or maybe you blocked them on the robots.txt file on purpose, but Google managed to index them. Either way, the first step is to check which URLs are having these issues before making any moves.
Note: keep in mind that this is not a small issue, and it can have a significant impact on your store’s SEO. So, don’t hesitate to reach out to an expert who can help you identify and resolve these issues.
How to fix the “Indexed, though blocked by robots.txt” issue?
To fix the “Indexed, though blocked by robots.txt” issue, you need to ensure that the file is correctly blocking the pages that you don’t want to be indexed. You can check the syntax of your robots.txt file or use the Google Search Console to check which pages are being blocked
Step-by-step Guide to Fix the Issue
Here is a short guide to fix issues related to the robots.txt file by using Google Search Console:
- Export all URLs in warning from Google Search Console: Go to the ‘Coverage’ report and select the ‘Valid’ tab, then select ‘Download’ and choose ‘All URLs’ to export a list of all URLs that are being blocked by the robots.txt file.
- Decide if you want them indexed or not: Review the list of URLs and decide which pages you want to be indexed by search engines.
- Unblock the URLs: Identify the rules blocking the pages in the robots.txt file and remove or comment out those lines.
- Test the changes: Use Google’s robots.txt Tester to test the changes and ensure that the pages you want indexed are no longer being blocked.
- Validate the fix: Hit the “VALIDATE FIX” button in the Google Search Console to request Google to re-evaluate your robots.txt against your URLs.
- Monitor the results: Monitor the coverage report for any other warning or errors.
Caution
Editing your robots.txt file is not difficult. But one misstep can have a significant impact on your web page indexing and SEO rankings. This kind of risk and the technicality involved is why you shouldn’t edit the robots.txt file yourself. It’s best if you hire professional services.
What Pages Shouldn’t be Blocked by Robots.txt?
Some pages are too important to be (accidentally) blocked. If so, you are likely to face decreased traffic, customer trust and search visibility. They include:
- Homepage: This is the most important page of your website and search engines should always be able to crawl and index them.
- Product pages: These pages contain important details about your products and should be indexed so that customers can find them via organic search and make purchases .
- Collection/category pages: These pages group together similar products and also help customers navigate your website. They should also be indexed.
- Blog pages: If you have a blog on your website, these pages should also be indexed as they can help drive traffic to your site and improve your SEO.
- About Us page: This page provides information about your company and can help build brand authenticity and establish trust with potential customers.
- Contact Us page: This page tells search engines and customers how to contact your business and should be visible.
- Privacy Policy and Terms of Service pages: These pages explain how your business handles customer data and should always be within the reach of search engines and customers.
- Sitemap page: This page provides a map of your website and can help search engines more easily crawl and index your site.
To cut it short, any page that contains valuable information that you want search engines and customers to be able to find shouldn’t be blocked. Other examples are customer reviews pages, FAQ pages, etc.
If you find that any of these pages is blocked by robots.txt, you should remove it from the robots.txt file and submit a new sitemap to Google for reindexing. But how about pages that should certainly be unindexed from the Robots.txt file? Let’s discuss those.
What Pages Should be Blocked by Robots.txt?
Not every page should be accessible to all. Some pages on your website contain sensitive or duplicate information that you don’t want search engines to index. Otherwise, you may trigger Google penalties or loss of customers. Here are a few examples of pages that you may want to block:
- Login pages: These pages typically contain customers’ private information and only authorized users should be able to reach them.
- Shopping cart and checkout pages: These pages may contain sensitive user details such as customer billing and shipping address, and should be blocked for security reasons.
- Pages with duplicate content: If you have multiple pages on your website with identical or similar content, it’s a good idea to block the duplicate pages and make the original version stand out.
- Pages with expired or low-quality content: If you have pages on your website that don’t offer much value to users, it’s best to block these pages. Such pages include: pages with outdated content, test pages, those under development, pages with expired special offers, media or PDF files, etc.
If later you want to unblock the blocked URLs, you will need to update your robots.txt file, and resubmit it to Google Search Console.